
This may seem like old-school programming style to you, but mouse clicks or a touch-screen cannot process big data files the way a keyboard’s command line can.
Way back in 1992, I realized that my computer-aided engineering work was very repetitive. I had new files to work with every day that were similar to the files that I worked on yesterday. Some times, these files had megabytes or even gigabytes of new data. I would edit them and make the same changes. The end results were different, because that day’s files were different.
This trend has only increased over the years since. With computers, test equipment and memory ever expanding, the need to process, reduce, condense, extract, extricate or summarize large amounts of data has exploded.
My work would move much faster if I had an editor that received its instructions daily from a third file. Such programs are called “stream editors”.
The data that I processed would come from simulators, emulators, logic analyzers, digital storage oscilloscopes, test equipment, source code in any language, electronic products, customers, etc.
The basic structure that I needed to do this had been in place since 1973 and has been ported to all operating systems ever since. It is based on filters using the standard input, standard output, error output, redirection and piping. It can be programmed from a shell script file and can create new files.
These filters cannot be used from a graphical user interface (GUI), because that would prevent access to their BATCH scripting, complex command-line parameters, I/O redirection and piping. They are accessible within a Windows PowerShell (Terminal) or Command Prompt, which was found under All Apps – Windows System, or All Programs – Accessories in older versions of Windows.
I test drove the popular filters that were readily available for all platforms in my search for a simple solution. The filters I tried are FIND, SORT, MORE, JOIN, GREP, EGREP, FGREP, ED, SED, MINISED, AWK, PERL, PAR, FOLD, FMT, PR, BASENAME, SPLIT, CSPLIT, CUT, DIRNAME, PYTHON, UNIQ, CMP, DIFF, DIFF3, ECHO, COMM, CUT, WC, TEE, TR, STRINGS, SWITCH, TAIL, REV, NL, PASTE, HEAD, CAT and FILT. I found these too cryptic, complex, constrained and numerous, so I decided to make my own. I created AFTER, BEFORE, COMBINE, ECHO2CON, ECHO2PRN, EXE2HEX, UPPER, LOWER, PREFIX, SUFFIX, SINGLE, SINGLES, SR, UNIQUE and WORDS during the early 1990s. These filled the voids that I missed in the popular filters.
The most useful and complex of them is SR. It performs global Search-and-Replacement, as word processors do, on any file type, replacing bytes, but from a command prompt or BATCH script.
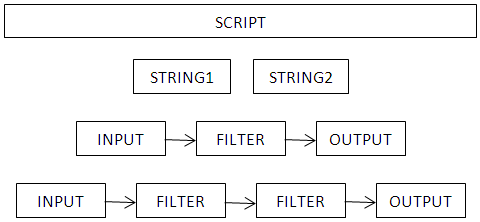
The command below replaces all portions matching STRING1’s pattern with STRING2. Input comes from the standard input (INPUT.FILE). Output is stored in the standard output (OUTPUT.FILE). If STRING2 is omitted, all portions matching STRING1’s pattern get deleted. In either case, all portions not matching STRING1’s pattern remain perfectly intact by default, even for binary files.
SR string1 [string2] [<input.file] [>output.file]
STRING1 and STRING2 may include literals, exactions, wildcards, delimiters, parsers and comparisons with modifiers, plus options, repeaters, jumps, counts and other drudges. These give SR the ability to execute complex pattern recognitions with flexible ways to replace its findings . Hence, SR is a programming language for BATCH scripts.
This Redirection (computing) article applies to all operating systems and explains how to use filters such as these. Think of the process like this:
History
I created the first version of SR in the early 1990’s. It was a 16-bit application running under DOS 2.0 or above or Windows Command.com. It reached maturity on 12-17-1997. I used that version in my daily work at Rogerson Kratos, Honeywell Aerospace, Rockwell Collins, Meggitt Fluid Controls and so on, until 2012.
I was provided with Windows 7/64-bit at Parker Aerospace, which made my 16-bit applications obsolete, so I upgraded my filters to 32-bit applications on 6/25/2012. My high-speed, 32-bit filter collection now includes SR, AFTER, BEFORE, UPPER, LOWER, PREFIX, SUFFIX, SINGLE, SINGLES, UNIQUE, WORDS and ECHO2CON, maintaining the original names.
Through the years, I was frequently disappointed in their speed. Whenever my filters took a long time to process my data, I used that time to look for ways to make them faster. The programs ended up with an input buffer and an output buffer to speed their execution. The sizes of both buffers default to the square-root of the address capacity of the platform. That’s 64KB for each on most modern computers.
If that much memory is not available, they repeatedly halve the amount until malloc works, with a lower limit of 1/16 of that starting amount.
Later, under some conditions, the programs might need more memory. They will then call realloc to double their input buffer’s size. This might also repeat.
When the programs have read all of their input, they call realloc to release their excess memory at the end of their input buffer.
Of course, at any time, they can issue an error message about insufficient memory or finding a pattern too complex, but this doesn’t happen unless there is something crazy going on.
All of this memory management speeds up execution by a factor of about 50 compared to using no buffers. This is how these programs can process data at over 100MB per second on modern computers.
On a macro scale, changing the size of the output buffer has little effect on speed, so these programs never call realloc to change the size of their output buffer. They also prioritize the input buffer to get more memory, in case there isn’t so much available. The output buffer could end up smaller than the input buffer, but not the other way around.
My reincarnation of all these filters (except ECHO2CON) is the same program. There is only one source for those 11 personae, which was last updated on Tuesday, 5-Feb-2016. The 10 other personae of SR automatically build SR’s complex STRING1 and STRING2 that will do the named function for you. Having one source for 11 filters balances out their error messages and personalities, plus it exterminates bugs 11 times faster.
Version Control
When I make a change to the source, I also increment the digit ending the file’s name. I change 9 to 0 and replace old files by the same name. This technique keeps the 10 most-recent versions of the source file to allow an easy route back to 9 prior versions if the new changes fail verification testing.
Verification
I maintain script files that completely test the 12 filters. The scripts use the same technique for version control as SR and the script versions match the filter versions being tested. All filter functions are exercised and verified by these scripts. The scripts are updated to verify new features as those features are added. Each execution of a filter verifies many of its features. The current script tests each filter several times, as shown here:
|
Filter |
Executions |
|
AFTER |
2 |
|
BEFORE |
3 |
|
ECHO2CON |
13 |
|
LOWER |
3 |
|
PREFIX |
3 |
|
SINGLE |
2 |
|
SINGLES |
3 |
|
SR |
61 |
|
SUFFIX |
5 |
|
UNIQUE |
5 |
|
UPPER |
3 |
|
WORDS |
5 |
|
Total |
108 |
New versions must pass all tests before any are released, verifying 12 bug-free programs!
Requirements and Validation
These filters were created out of my needs for fast, productivity software. The list of features grew as I found new needs. New features were put to use the same day and were validated by fulfilling that new, real-world need. This cycle continued for years to produce ideal filters for my engineering and big-data needs.
As new needs arose, I documented their requirements in a file by the same name as the filter affected. These files were used as both their software requirements documents and their help files, so these files must follow wherever the filters go.
Filter Functions
The following are the basic functions of the filters.
| AFTER | includes the remainder of each line AFTER the first tabulation |
| BEFORE | includes the beginning of each line BEFORE the first tabulation |
| ECHO2CON | sends its standard input to both its standard output and standard error devices |
| LOWER | translates every letter to LOWER-case |
| PREFIX | adds a PREFIX to the beginning of each line |
| SINGLE | deletes blank lines |
| SINGLES | reduces sets of one or more spaces or tabs to a single space |
| SR | Search-and-Replacement |
| SUFFIX | adds a SUFFIX to the end of each line |
| UNIQUE | omits recurrences of duplicate lines |
| UPPER | translates every letter to UPPER-case |
| WORDS | separates WORDS, listing one word per line |
Bytes of Unicode are processed left-to-right in the UTF format used. Bytes of UTF-8 are ignored unless each byte is matched by an exaction.
Portability
I wrote most of my early filters in assembly language for the Intel 8086, but my new filters are now all written in C. They are portable to and recognize EoLs from Unix, GNU/Linux, Xenix, Multics, AIX, Acorn BBC, BeOS, FreeBSD, RISC/RISC spooled text output, Mac OS, OS/2, OSX, Amiga, Apple II, Commodore, Windows, DOS, TOPS-10, RT-11, TRS-80, CP/M, MP/M, TOS, Symbian and Palm operating systems. The input and output file sizes are unlimited, while the size of findings is only limited by your computer’s memory.
Conclusion
I find that I can do 90% of my big data processing computer work with scripts that use these filters. The time it took was reduced by a factor of 10, giving me much more time to do the hands-on tasks.
Compilers
I compiled using Borland Turbo C originally, but it is now obsolete. For 32-bit Windows platforms, I have tried CYGWIN, LCC-Win32, Pelle Orinius’ C for Windows, MinGW and Microsoft Visual C++ 2008 Express Edition. The winners are MinGW, which produces stand-alone .EXE files and CYGWIN, which produces smaller .EXE files that require CYGWIN1.DLL to be in the path. This is a 3MB file included in the CYGWIN installation, which needs 1GB. I opted for MinGW to distribute stand-alone EXE files.
– Gareth B. Dolby

Good site you’ve got here.. It’s difficult to find high quality writing like yours
nowadays. I really appreciate people like you!
Take care!!
Feel free to surf to my web page: online marketing blog
I’m gone to say to my little brother, that he should also pay a
visit this website on regular basis to get updated from
newest gossip.
Also visit my web-site mp3 player
I do trust all the ideas you’ve introduced on your post.
They are very convincing and will definitely work. Nonetheless, the posts are very brief for newbies.
May you please extend them a bit from next time? Thank you for the post.
Feel free to visit my website :: negligence in nursing
What’s up it’s me, I am also visiting this site daily, this web page is really nice and the people are actually sharing nice thoughts.
Feel free to surf to my web site: pre action protocol clinical negligence
Good article. I will be going through a few of these issues
as well..
my website :: mp3 music download
Do you mind if I quote a few of your posts as long as I provide credit and sources back to
your blog? My blog site is in the very same
area of interest as yours and my users would truly benefit from a lot of the information you present here.
Please let me know if this ok with you. Thanks a lot!
Precisely where else should you end up for oil on driveway resources?
What’s up friends, pleasant piece of writing and good arguments commented at this place, I am really enjoying
by these.
Also visit my homepage; clinical negligence definition
Wow, this piece of writing is good, my sister is analyzing
these kinds of things, thus I am going to tell her.
Take a look at my blog post … blog making
It’s very trouble-free to find out any topic on web as compared
to books, as I found this piece of writing at this site.
Here is my page … http://skhn3.tumblr.com
Hi there, i read your blog occasionally and i own a similar one and i was just curious if you
get a lot of spam comments? If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me mad so any help is very
much appreciated.